We’re still in the process of migrating from Nintex RPA LE to Nintex RPA, and one of the features we’re severely missing is how easy RPA LE handled the import of data. With RPA LE, you could have it import a data file (like a CSV), and it would automatically populate a “Data” section with all of the available headers in the file. You could then loop through that data, and easily reference a property from the current iteration.
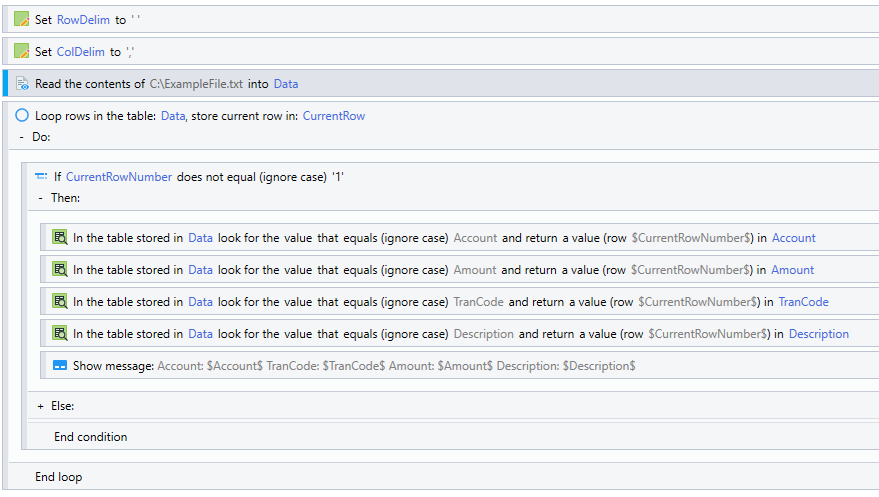
With Nintex RPA, this process seems MUCH more cumbersome. It seems like you need to import the file as text into a variable, then iterate through that variable with a specified row delimiter. To pull out a specific property of the current row, you need to get that index of the needed column using a column delimiter, and hope the layout of the file doesn’t change. I know that I could set it up at the beginning of the loop to pull out each index of the row into a named property - it’s just a lot of work that we didn’t have to do with the legacy product.
So, for those that iterate through a set of data with a semi-large amount of fields - Do you have an efficient and easy way reference the necessary properties for each row?
Thank you!