Hello All,
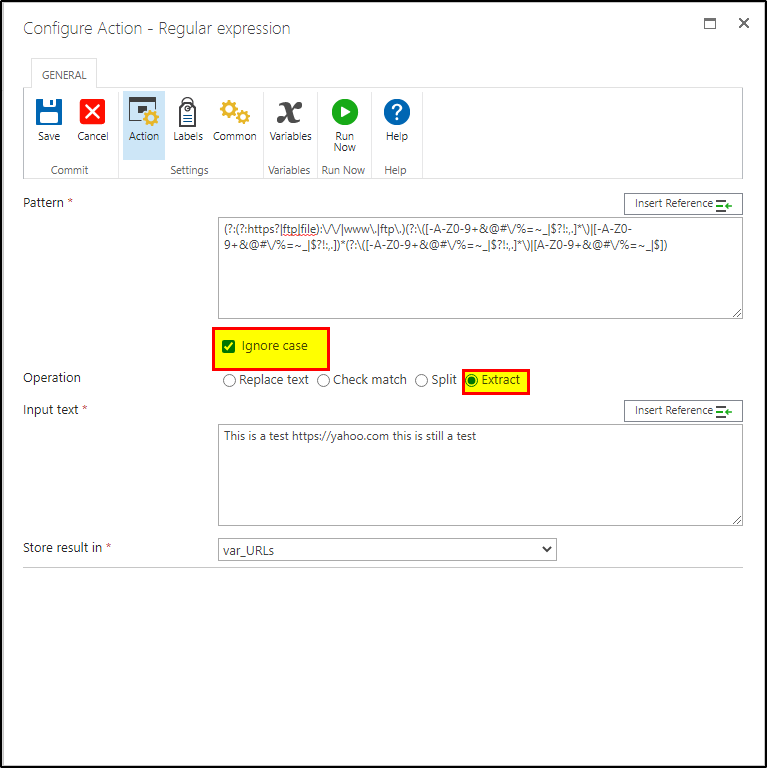
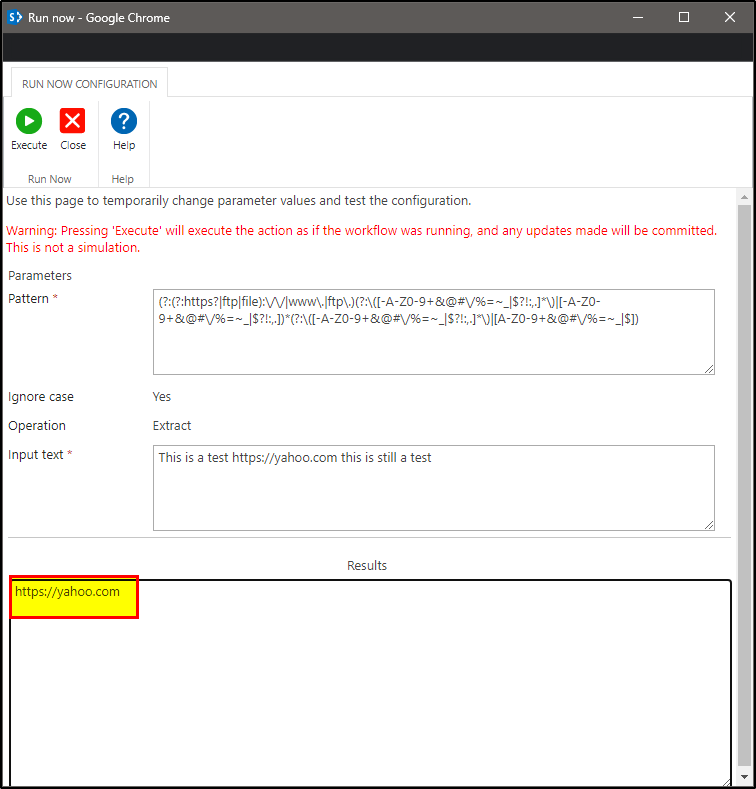
I need to extract URL(s) from a text string using the regex function. A sample string may be something like: "This is a test https:||yahoo.com this is still a test" (I had to replace the // with || to be able to post a URL)
I found a regex expression online that works great when I test it with a regex tester online, however the Nintex regex action returns nothing. Why would this regex expression work on a regex tester but not for nintex?
/(?:(?:https?|ftp|file)://|www.|ftp.)(?:([-A-Z0-9+&@#/%=~_|$?!:,.]*)|[-A-Z0-9+&@#/%=~_|$?!:,.])*(?:([-A-Z0-9+&@#/%=~_|$?!:,.]*)|[A-Z0-9+&@#/%=~_|$])/igm