
In receiving hundreds of Insurance Claims per day, we going to look into how RPA solution can help insurance companies save efforts and money hiring tens of people to do the capturing of claims, from scanned documents to claim processes.
In this blog post, I am going to share how I convert a PDF file to an image for the OCR purpose. Converting PDF to image is not a mandatory step, but in the RPA Claim Processing exercise, it is a step I will need to overcome challenges that we going to discuss later.
We will need some basic setup for the PDF to Image Conversion purpose, this is shared in the following paragraphs.
Environment and Steps Setup:
1. Python 3.7.4
2. ImageMagick 6.9.10 Q8 (64-bit)
3. Project speicific Python Virtual Environment
4. Python Wand library package install to the virtual environment
5. creating a Python action in Foxtrot RPA
1. Install Python 3.7.4
I am using Python 3.7.4 version on windows 10 for this exercise, I am making assumption if you are looking at running a python action in Foxtrot, it means you should have knowledge and with python installed in your environment. In case you don't, you may download and install python from python.org/downloads/windows/ for the purpose of this exercise.
Below is the capture of where I've got the intallation for python
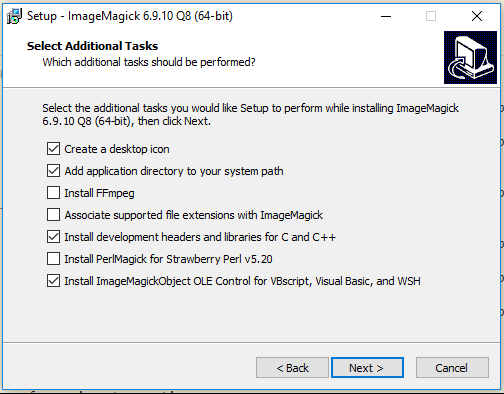
2. ImageMagick 6.9.10 Q8 (64-bit)
ImageMagick is a popular open source image conversion library which has different extension or wrapper library in different programming languages. The installation can be found from the ImageMagick site at imagemagick.org. I have selected what I needed for my exercise as captured below, you will not need the ImageMagick OLE Control for VBScript, Visual Basic, and WSH if you are not going to use the library for the respective languages.
3. Project speicific Python Virtual Environment
Following the best practice of Python development, we avoid installing packages into a global intergreter environment. We going to create a project-specifi virtual environment for our exercise. To do that simply create a virtual environment under your project folder:
py -3 -m venv .venv
4. Python Wand library package install to the virtual environment
Now, we can activate the virtual environment using the below command and to install required package for our project
.venvscriptsactivate
and install the Wand package
python -m pip install Wand
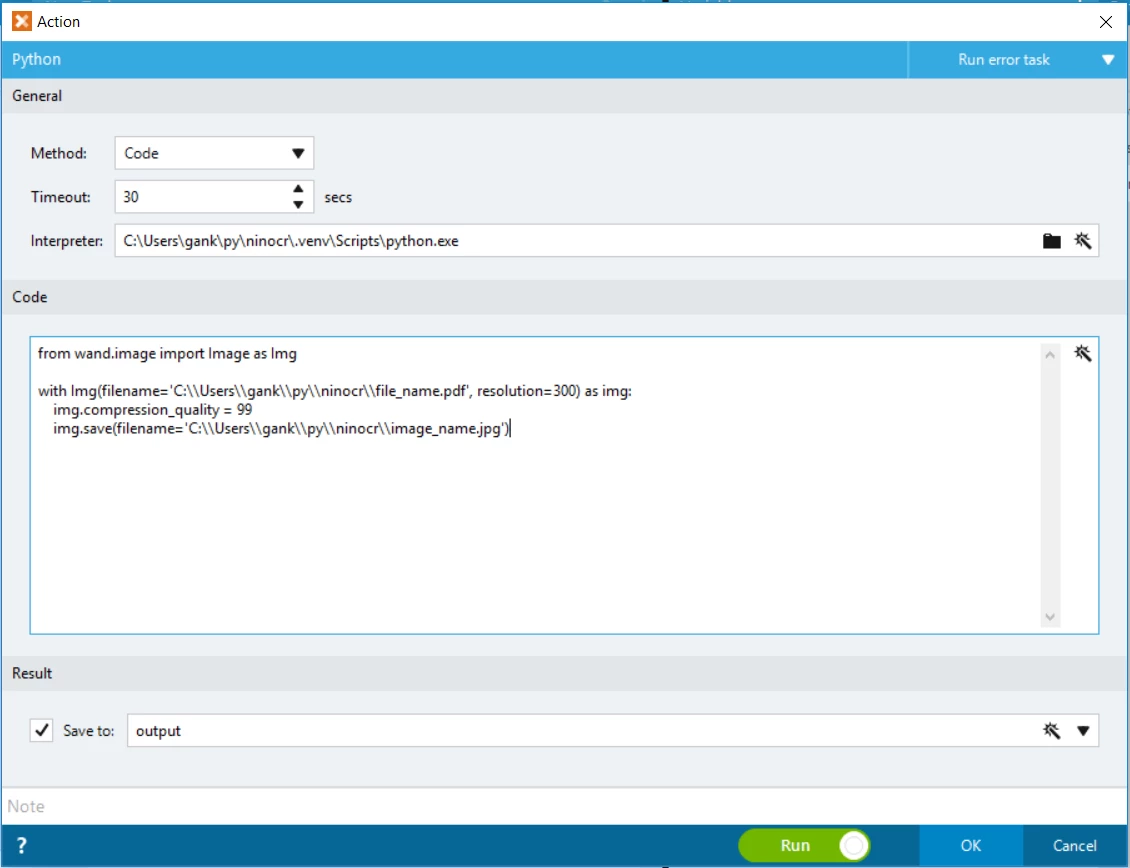
6. Create and test the Python action
Now you may add a Python action in your Foxtrot project to convert PDF file into an image file. I have below code for the testing purpose:
from wand.image import Image as Img with Img(filename='C:\Users\gank\py\ninocr\file_name.pdf', resolution=300) as img: img.compression_quality = 99 img.save(filename='C:\Users\gank\py\ninocr\image_name.jpg')
Here is the screen capture of my Python action:
With the above steps, we have successfully achieving what we need - converting any scanned PDF into a image file. This is the first part of the exercise where in the later blog post(s), we are going to OCR the image file.
Note: Converting PDF to Image is not a mandatory steps for OCR a document, but in our scenario, I am going to use image file for the purpose, will explain further the objective behind.
Before I further explain how we going to use the converted image for the OCR purpose, let us take a look and learn about how we can use the Nintex Foxtrot RPA's Simple OCR action, I have it covered in RPA Claim Processing - Part 2: Nintex Foxtrot Simple OCR
