Hello!
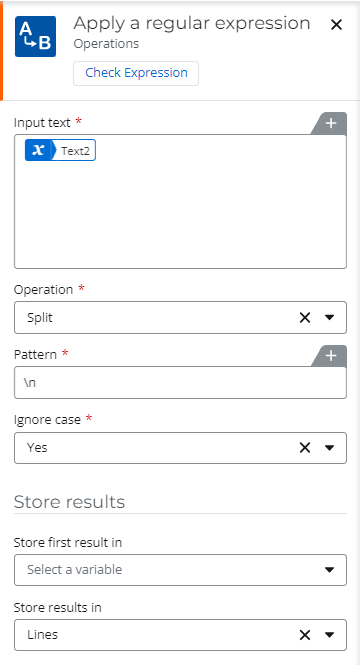
Just wondering if this is feasible/possible, I’m trying to extract line by line of a multiline text field (setting as enhanced rich text) using regex extract.
Example:
All the world's a stage,
And all the men and women merely players;
They have their exits and their entrances,
And one man in his time plays many parts,
His acts being seven ages. At first the infant,
Mewling and puking in the nurse's arms.
Goal: Extract each line and save in a collection variable for further processing.
Regex:
^\w.*$
Different variant: (?<=^).*(?=[\r\n])
When I try it on regex101.com or even when I paste the text directly, it seems to work, and I’m able to see each line. However, when I test it on Nintex Workflow and reference the actual multiline field, it fails. Am I missing something here? Could it be due to the list item’s multiline text field being set as enhanced rich text?
Thank you for any insights!