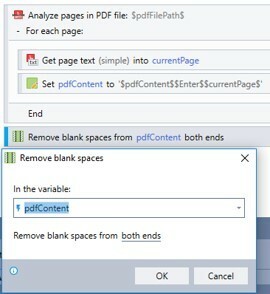
1. Use the Analyze digital PDF file advanced command. This command can only be used on a digital PDF document (document that’s converted from a soft copy document (e.g. Word, Excel, Powerpoint, etc) and not applicable to scanned document
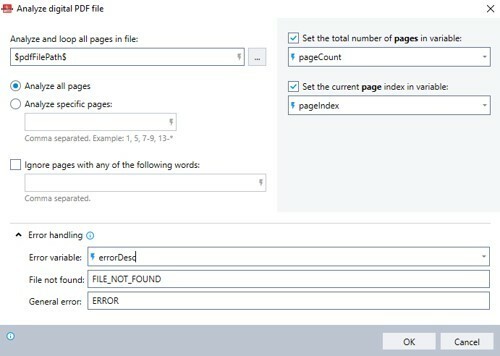
2. An Error variable can be defined to identify the specific error if an issue occurs during the execution
3. Use the Page: Get Text advanced command within the Analyze digital PDF file advanced command to extract the contents by page
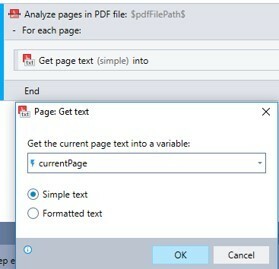
4. As the Analyze digital PDF file advanced command is a loop command which gets the contents by page, there is a need to append all the contents obtained into a variable which provides you with the full contents of the extraction in 1 variable. This can be achieved through the use of concatenation of values into a single variable after each page extraction
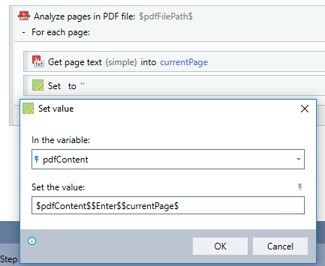
5. At the end of the execution, you should have a variable (e.g. $pdfContent$) that contains the entire extracted content (excluding images) from the PDF document. You will need to use the Remove blank spaces advanced command to remove any blanks on both ends to clean up the variable and ensure there’s no unwanted white spaces in the final variable