

Hi,
I have faced this issue thrice now. I am not able to access any feature of appit for 3-4 hours and trying to access them only throws exception.
I am posting a couple of screenshots :
This is while trying to open a workflow, something similar also pops up when trying to open reports from the default page of appit, or trying to browse through items in the management console.
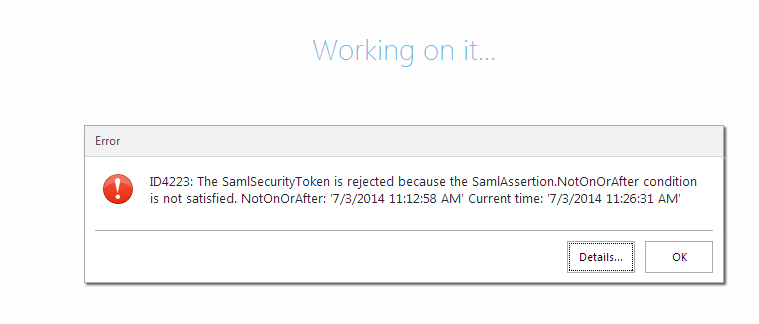
- Trying to access the worklist throws something like
ID4223: The SamlSecurityToken is rejected because the SamlAssertion.NotOnOrAfter condition is not satisfied. NotOnOrAfter: '7/3/2014 11:12:58 AM' Current time: '7/3/2014 11:19:13 AM'
- Type:
System.IdentityModel.Tokens.SecurityTokenExpiredException
- Source:
System.IdentityModel
- Stack Trace:
at System.IdentityModel.Tokens.SamlSecurityTokenHandler.ValidateToken(SecurityToken token)
at SourceCode.Security.Claims.ClaimsResolver.ValidateSaml11TokenXml(String tokenXml, List`1 issuers)
at SourceCode.Security.Claims.SecurityClaims.ResolveClaimsToUserFullyQualifiedName(ClaimsTokenType tokenType, String tokenXml, Object issuers, Object claimTypeMappings)
at SourceCode.Hosting.Server.Runtime.HostSecurityManager.GetClaimsUserName(String tokenXml, ClaimsTokenType tokenType, ClaimsVersion claimsVersion)
at SourceCode.Hosting.Server.Runtime.HostSecurityManager.AuthenticateIIdentitySession(String sessionCookie, String tokenXml, ClaimsTokenType tokenType, Boolean isPrimarySecurityEntity, String authReqSource, ClaimsVersion claimsVersion)

